해당 글은 다음 UNSEEN 대비 4. C++ 주요 컨테이너 (1) (array, vector, list) (tistory.com)에서 다루지 않은 나머지 컨테이너를 다루는 글입니다.
5. 맵(map)
맵(std::map)은 키(Key)와 값(value)의 쌍들을 저장하는 이진탐색트리 기반의 컨테이너이다.
이때, 키는 중복될 수 없다.
맵의 각 원소는 std::pair<key,value>로 저장된다.
pair는 순서쌍을 가리키는데 여기서는 pair.first에 key가, pair.second에 value가 저장된다.
C++에서 맵은 Key를 기준으로 자동 정렬되는데, 내부적으로는 레드블랙트리로 구현된다.

맵 생성
맵을 생성하는 대표적인 방법에는 map<<key_type>, <value_type>> <name>로 빈 맵을 생성하거나 map<<key_type>, <value_type>><name>(const map& x)로 기존 맵을 복사하는 것이 있다.
#include <map> // 헤더 파일
// 예시
std::map<std::string, int> heightMap; // 키 맵
std::map<std::string, int> copiedMap(heightMap); // 복사 생성된 맵삽입: insert()
insert(const value_type& value)로 새 요소를 맵에 삽입할 수 있다. 이때 반환되는 값은 std::pair<iterator, bool>로 반복자 iterator와 삽입 결과 bool의 쌍이 나온다.
키를 중복으로 삽입할 수 없다는 점을 주의하자.
std::pair<std::string, int> data("Bob", 173); // map의 요소는 std::pair이다.
heightMap.insert(data);operator[]
mapped_type& operator[](const Key& key);
배열을 사용하듯이 []를 통해 원하는 키 값에 해당하는 요소를 가져올 수도 있다.
std::map<std::string, int> simpleMap;
simpleMap["Sam"] = 10; // 새 요소 삽입
simpleMap["Sam"] = 30; // "Sam"의 값을 30으로 변경이때 []로는 참조 값이 반환되어 위와 같이 원본 데이터를 수정할 수도 있다.
map에 해당되는 키가 없으면 새 요소를 삽입한다. 해당되는 키가 있다면 그 요소의 값을 변경한다.
키가 없으면 삽입하다 보니, 없는 키를 읽어올 때 잘못하면 데이터가 새로 추가될 수도 있다. 따라서 데이터 탐색을 위해서는 find를 써야 한다.
원하는 데이터 찾기
원하는 요소를 찾을 땐 find 함수를 사용할 수 있다.
iterator map(const Key& key);
map에서 key를 찾으면 대응되는 값을 가리키는 반환자를 반환하고, 못 찾으면 map.end()를 반환한다.
std::map<std::string, int> simpleMap;
std::map<std::string int>::iterator it = simpleMap.find("Alice");
if (it != simpleMap.end())
std::cout << "요소를 찾았습니다" << std::endl;
else
std::cout << "탐색에 실패했습니다.\n" << std::endl;맵 탐색하기
맵은 반복자를 통해 탐색할 수 있다.
for (auto iter = simpleMap.begin(); iter != simpleMap.end(); iter++)
{
cout << iter->first << " " << iter->second << endl;
}범위 제한을 하지 않는다면 이렇게 사용할 수도 있다.
for (auto iter : simpleMap)
{
cout << iter->first << " " << iter->second << endl;
}기타
이외에도 erase 함수로 키나 반복자를 주어 요소를 삭제할 수 있다.
clear()를 사용하여 map을 비울 수도 있다.
map은 기본적으로 key 값 기준 오름차순으로 정렬된다. 내림차순으로 정렬 기준을 바꾸고 싶다면 greater<>를 넣어주면 된다.
map<int, string, greater<int>> m; // 내림차순으로 정렬key로 객체가 들어가거나 할 땐 따로 비교 함수를 만들어서 넣어주면 된다.
struct InfoComparer
{
// Info 객체에 대한 비교 함수
bool operator()(const Info& lleft, const Info& right) const
{
return (left.getName() < right.getName());
}
}
// Main.cpp
std::map<Info, int, InfoComparer> m;장단점
std::map은 균형 이진 탐색 트리의 일종인 레드블랙트리를 사용하여 삽입, 삭제, 탐색이 빠르다(O(logN)).
다만 자동으로 정렬되는 것이 필요하지 않을 때는 굳이 map을 사용할 이유가 없다. map은 레드블랙트리 기반이기 때문에 삽입할 때마다 트리의 균형을 맞춰야 한다. 게다가 map은 해시맵, 해시테이블과 달리 상수 시간 O(1)에 데이터를 처리하지 못한다.
만약 해시맵 기반의 자료구조가 필요하면 unordered_map을 사용해야 한다.
- 삽입, 삭제, 탐색: 시간 복잡도 O(logN)
6. 정렬 안 된 맵(std::unordered_map)
std::unordered_map은 기존 std::map의 문제를 해결하기 위해 나온 컨테이너로 C++ 11부터 적용된다.
기존 std::map은 O(logN)의 시간 복잡도를 갖으므로 요소의 삽입/삭제가 빈번하면 성능 저하가 있다.
반면 std::unordered_map은 이름처럼 정렬을 수행하지 않기 때문에 시간 복잡도가 O(1)이다.
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
std::unordered_map<std::string, int> unordered;
unordered["Alice"] = 50;
unordered["Bob"] = 60;
unordered["Sam"] = 70;
for (auto it = unordered.begin(); it != unordered.end(); it++)
std::cout << it->first << ": " << it->second << std::endl;
return 0;
}이렇게 입력하면, 결과가 정렬되지 않고 랜덤하게 나타난다.
std::unordered_map은 map과 마찬가지로 키와 값의 쌍(pair)을 저장하며 키도 중복 불가이다. 하지만 Hash Map 기반으로 만들어진 컨테이너이기 때문에 정렬을 수행하지 않는다. 이 컨테이너는 삽입, 삭제에 걸리는 시간 복잡도가 O(1)이다.
해시맵(Hash Map)
std::unordered_map에서 사용되는 자료구조는 해시맵 또는 해시테이블로, 여러 개의 버킷을 두고 해시 함수(Hash function)를 통해 색인(index)한다.
해시 함수는 키 값을 정수로 변환하는 역할을 한다. 동일한 키 값이 주어지면 동일한 정수로 변환해 준다. 하지만 정수 값을 통해 키 값을 구하는 것은 불가능하다.
해시 함수를 이용하면 함수 한 번으로 데이터가 들어갈 인덱스를 구할 수 있어 탐색이 훨씬 빠르다.
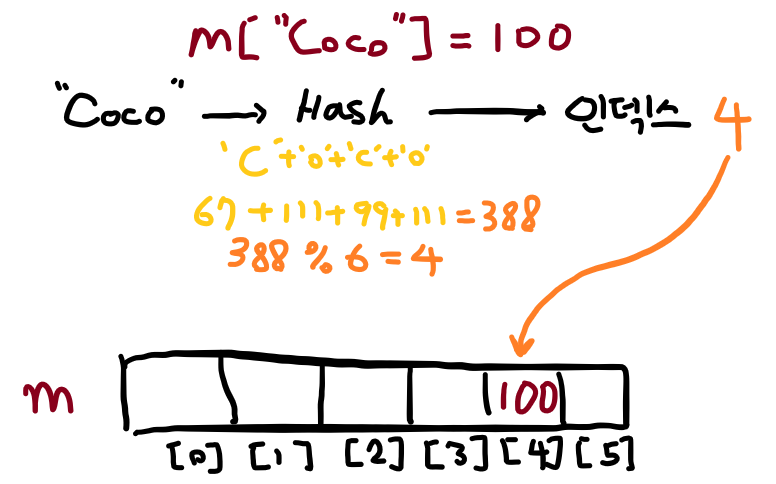
예를 들어 해시 함수를 ASCII 값의 합이라 하고, 그 합을 버킷의 수의 6으로 나눈 나머지(sum % 6)를 인덱스로 하자. 해시맵에 “Coco”를 넣으면 (ASCII 코드의 합 % 6) = (388 % 6) = 4가 되어 4번 버킷에 데이터가 들어가게 된다.
하지만 버킷의 수보다 키의 개수가 더 많다. 그래서 여러 개의 키를 넣었을 때 해시 함수의 값이 같은 경우가 있다. 이러면 하나의 버킷에 둘 이상의 데이터가 들어가는데 이를 해시 충돌(Hash collision)이라 한다.
해시 충돌 해결법
해시 충돌을 해결하는 방법에는 개방 주소법(Open Addressing)과 연쇄법(Chaining)이 있다.
(1) 개방 주소법(Open Addressing): 해시 충돌이 일어나면 다른 버킷에 데이터를 삽입한다. 이때, 다음 버킷을 찾는 방법으로는 선형 탐사(Linear Probing), 제곱 탐색(Quadratic Probing), 이중 해시(Double Hashing)가 있다.
- 선형 탐사: 충돌 발생 시 바로 다음 버킷이나 몇 개를 건너뛴 곳에 데이터 삽입
- 제곱 탐색: 충돌 발생 시 제곱 개수만큼 건너뛴 버킷에 데이터 삽입(1, 4, 9, 16, …)
- 이중 해시: 이중 해시는 충돌 발생 시 다른 해시 함수를 적용하여 몇 칸만큼 건너뛸지 계산한다. 다른 방법은 첫 번째 해시 값이 같으면 탐색했을 때에도 충돌이 계속 발생한다. 이중 해시는 점프할 칸까지 결정하기 때문에 훨씬 충돌이 적다.
(2) 연쇄법(Chaining): 충돌이 일어나면 같은 버킷에 데이터를 넣어준다. vector나 array를 만들어서 넣어주거나 연결리스트 기반으로 만들어줄 수 있다.
How does C++ STL unordered_map resolve collisions? - Stack Overflow
C++에서는 연쇄법을 사용한다. 탐색 시 충돌이 일어나면, 해당 버킷 내에서 다시 데이터를 탐색해야 한다. 그래서 최악의 경우 O(N)의 탐색 시간이 걸린다.
bucket size가 커질수록 버킷이 많아져서 충돌이 줄어들 수 있다.
unordered_map은 요소의 개수가 많아질수록 충돌을 방지하기 위해 버킷의 수를 늘린다.
장단점
std::unordered_map은 해시 맵, 해시 테이블 기반이다. 따라서 해시 충돌이 없을 경우 탐색 시간이 상수 시간이지만, 충돌이 발생하면 O(n)까지 시간이 걸릴 수 있다.
std::map과 달리 자동으로 정렬되지 않는 컨테이너이므로, 정렬이 필요하면 map을 사용해야 한다.
요소가 많아질수록 버킷도 많아져서 메모리 사용량이 커진다.
탐색 시간은 다음과 같다.
- 해시 충돌이 없을 경우 O(1)
- 최악의 경우 O(n)
참고
POCU 아카데미 'COMP3200: C++ 언매니지드 프로그래밍'
[C++][STL] map 사용법 정리 (tistory.com)
[C++ STL] std::unordered_map(연관 컨테이너) (tistory.com)
[IT 기술면접 준비자료] 해시(Hash)와 해시충돌(Hash Collision) (tistory.com)
'UNSEEN' 카테고리의 다른 글
| UNSEEN 5. 게임 알고리즘 (2): FSM, BT (3) | 2024.01.30 |
|---|---|
| UNSEEN 5. 게임 알고리즘 (1): A*, 쿼드트리 (1) | 2024.01.30 |
| UNSEEN 대비 4. C++ 주요 컨테이너 (1) (array, vector, list) (2) | 2024.01.28 |
| UNSEEN 대비 3. 메모리 영역 (1) | 2024.01.25 |
| UNSEEN 대비 2. C++ 언어의 특징 (0) | 2024.01.25 |




댓글