ECS가 무엇인지, 언어와 관련 없이 개념을 정리해놓고 싶어서 글을 정리해 봅니다.
공부한 바를 제가 이해한 대로 정리한 것이므로, 틀린 점이 있다면 가감 없이 지적해 주시면 감사하겠습니다.
해당 글은 특히 다음 영상을 주로 참고하였습니다(https://www.youtube.com/watch?v=7UphiG8UtTg).
1. DOD를 어떻게 적용해야 할까?
ECS에 대해 이야기하려면, DOD, 즉 데이터 지향 설계에 대한 이야기를 한번 짚고 넘어가야 한다. ECS란 DOD를 어떻게 적용할지에 대한 고민에서부터 출발한 개념이기 때문이다.
데이터 지향 설계(DOD; Data-Oriented Design)란 객체 지향 설계(OOD; Object Oriented Design)에서 발생할 수 있는 비효율적인 데이터 접근을 막기 위한 새로운 패러다임이다.
예를 들어, 일반적으로 우리가 짜는 코드에서는 캐시 메모리를 고려하지 않아서 비효율적인 면이 발생할 수 있으며, 데이터의 구조와 그에 대한 접근 방식에 따라 성능이 달라질 수 있다. 즉, 하드웨어를 함께 고려하여 프로그래밍해야 프로그램을 최적화할 수 있다.
왜 DOD가 필요할까?
예를 들어, 게임 내에 있는 캐릭터에 대해 속도를 업데이트하는 코드를 생각해 보자. 보통 GameObject 클래스를 두고, 그에 대한 속도 멤버를 두고, Update 함수를 호출하면 속도를 갱신하는 식으로 구성할 수 있다.
// 출처: http://deplinenoise.wordpress.com/2013/12/28/optimizable-code/
class GameObject {
float m_Pos[2];
float m_Velocity[2];
char m_Name[32];
Model* m_Model;
// ... other members ...
float m_Foo;
void UpdateFoo(float f)
{
float mag = sqrtf(
m_Velocity[0] * m_Velocity[0] +
m_Velocity[1] * m_Velocity[1]);
m_Foo += mag * f;
}
}전통적인 관점에서는 위에서 성능 상에 문제가 되는 부분은 sqrt이다.
수학 계산 중에서 루트를 계산하는 sqrt는 꽤나 연산에 많은 비용이 들어가는 편이다. 단일 산술 연산이 많아야 3~4 cycle 정도 걸리는 데에 반해, sqrt는 보통 10 cycle 이상의 시간이 걸리기 때문이다.

하지만 실제로 병목이 되는 부분은 캐시 메모리이다.
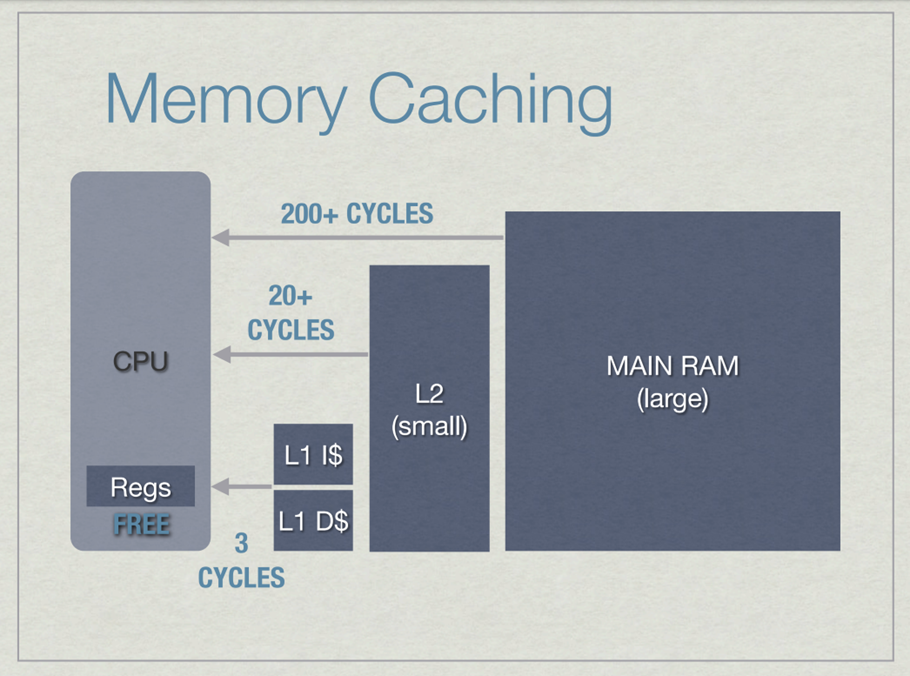
위 그림은 L1 캐시, L2 캐시, Main RAM으로부터 데이터를 가져오는 데에 얼마나 Cycle이 소요되는지를 표현한 그림이다.
CPU에서 계산을 수행하려면 데이터를 CPU 내에 있는 레지스터로 가져올 필요가 있다. 그런데 Main RAM에서 가져올 경우엔 200 Cycle 이상의 시간이 소요되기 때문에, CPU와 Main RAM 사이에는 중간 저장 장치로 L1, L2 등의 캐시(Cache)를 두도록 한다. 여기에서 주목할 점은, 만약 캐시에 데이터가 있다면 캐시에서 가져오지만, 캐시에 데이터가 없다면 Main RAM에서 데이터를 가져와야 한다는 것이다. 이 경우 Cache Miss가 일어났다고 부른다.
Cache Miss가 발생했을 때 걸리는 시간은 최소 200 Cycle이다. 이는 sqrt를 실행하는 데에 걸리는 시간보다 훨씬 많을 수밖에 없다.
다시 코드를 보면, UpdateFoo에서는 값 m_Velocity[0], m_Velocity[1]을 활용하여 계산을 수행하고, m_Foo에 그 값을 업데이트한다.
당연하지만 게임 내에서 사용하는 데이터는 너무나도 많기 때문에, UpdateFoo를 실행할 땐 높은 확률로 m_Velocity에 대해 Cache Miss가 발생하고, 이 시간이 sqrt를 실행하는 데에 걸리는 시간보다 길 수밖에 없다.
따라서 Cache Miss 현상을 조금이라도 줄이려면, 데이터를 한 곳에 모아놓고, 한 번에 업데이트하는 것이 좋다.
DOD를 적용하면 어떻게 될까?
DOD(Data-Oriented Design)는 이러한 하드웨어적 환경도 함께 고려하여 성능을 최적화한다.
struct FooUpdateIn {
float m_Velocity[2];
float m_Foo;
};
struct FooUpdateOut {
float m_Foo;
};
void UpdateFoos(const FooUpdateIn* in, size_t count, FooUpdateOut* out, float f)
{
for (size_t i = 0; i < count; ++i) {
float mag = sqrtf(
in[i].m_Velocity[0] * in[i].m_Velocity[0] +
in[i].m_Velocity[1] * in[i].m_Velocity[1]);
out[i].m_Foo = in[i].m_Foo + mag * f;
}
}DOD를 적용하면 코드를 위와 같이 개선할 수 있다.
위 코드의 특징은 (1) 데이터를 FooUpdateIn, FooUpdateOut 배열로 인접시키고, (2) UpdateFoos로 한 번에 여러 데이터를 업데이트한다는 점이다.
FooUpdateIn은 배열의 형태로 모이게 되어, Cache Miss가 발생하더라도 Cache line 크기(일반적으로 64 Byte)에 따라 여러 개의 Velocity 요소를 가져오므로 훨씬 Cache Miss가 덜 발생하게 된다.
특히나, 여기서 한 번에 업데이트하는 count를 Cache line 크기의 배수로 딱 맞춘다면, 훨씬 최적화할 수 있다.
이렇게 되면 Cache Miss로 인한 성능 하락을 줄일 수 있게 된다.
DOD를 잘 적용하면 객체 지향 프로그래밍(OOP; Object Oriented Programming)에서 문제가 되었던 성능 문제, 디버깅의 어려움 등을 해결할 수 있다.
DOD에 더 궁금하신 분들은 다음 강연에서 잘 설명하므로 한번 들어보도록 하자.
https://youtu.be/rX0ItVEVjHc?si=bsJljTZc1CVvDTgz
어쨌거나 DOD란 정말 좋은 아키텍처 설계 방법이지만, 잘 적용하기란 쉽지 않다.
단순히 속도를 업데이트하는 코드 한 줄을 짜는 데에만 해도 메모리와 캐시 미스 문제를 고려해야 하며, 코드의 복잡성이 커질수록 프로그래머는 더 많은 고민을 해야 한다.
따라서 DOD를 실무에서 좀 더 잘 적용하려면, 좀 더 정형화된 패턴을 살펴볼 필요가 있다.
2. ECS(Entity Component System)이란?
DOD의 핵심을 단순화하자면, 하드웨어(특히 캐시 메모리)를 잘 활용하는 것에 있다.
최대한 캐시에 데이터를 눌러 담아서, Main RAM으로부터 LOAD 하는 일을 줄여서 최적화한다.
위 예제에서 봤던 코드를 좀 더 일반화하면, DOD를 적용했을 때 효율적인 이유는 다음과 같이 생각할 수 있다.
- 클래스별로 메모리를 연속적으로 모은다(메모리 Packing).
- for loop로 같은 종류의 객체를 순회한다.
실제로 단순히 데이터를 중앙에서 모아서 처리하기만 해도 효율이 증가한다.
다음 예시는 언리얼 엔진의 예시이다.
언리얼 엔진에서의 월드 내 객체는 액터라 하는데, (1) 액터를 생성하여 한 곳에 저장하고 (2) 업데이트할 때 ActorManager에서 한 번에 처리하도록 변경하였다.
위와 같이 변경하였을 때, 업데이트 시간이 매 프레임 8.2ms에서 4.7ms로 43%만큼 줄어들게 되었다고 한다.
(출처: https://www.jooballin.com/p/unreal-engine-data-oriented-design)
이를 좀 더 본격적으로 체계화해 보자.
ECS의 개념
OOP에서는 객체를 정의할 때 '상속'으로 접근한다.
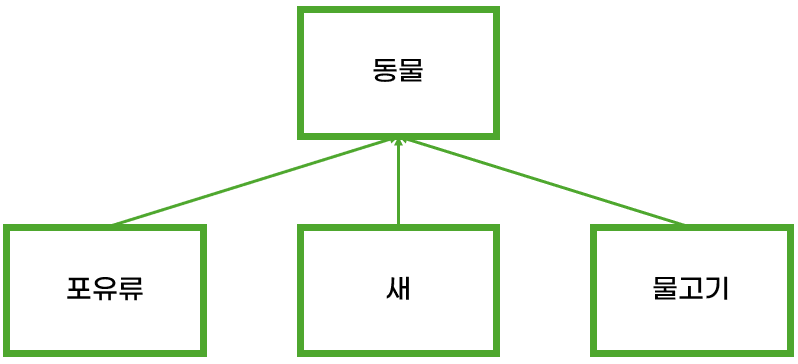
- 클래스를 상속받은 자식이 있을 수 있다.
- 최대 하나의 부모만 가진다.
OOP에서는 객체가 갖는 특징을 표현하기 위해 상속을 이용한다. 동물이 갖는 특징을 똑같이 갖는 포유류, 새, 물고기 등의 종이 필요하다면, '동물' 클래스를 상속받아 '포유류', '새', '물고기' 클래스를 만드는 식이다.
OOP에서 여러 개의 특징을 가져, 여러 부모가 필요한 경우도 존재한다. 위의 예시에서는 포유류이자 새인 종을 예로 들 수 있다. 전통적인 OOP에선 포유류이자 새인 경우엔 두 개 클래스를 상속받아야 한다. 그러나, 다중 상속은 대부분의 언어에서 금지 또는 제한적으로 사용하기를 권장하기 때문에 해결하기 어렵다. 다중 상속을 받았을 때 '죽음의 다이아몬드 문제'가 발생할 수 있기 때문이다.
OOP에서는 해당 문제를 회피하기 위해 인터페이스를 둘 수 있다.
반대로, ECS(Entity Component System)은 다르게 접근한다.
ECS는 데이터를 조직화하는 방법 중 하나로, 이름 그대로 엔티티(Entity), 컴포넌트(Component), 시스템(System)으로 나누어 시스템을 처리하도록 한다.

ECS에서는 객체가 갖는 특징을 상속이 아니라 컴포넌트로 표현한다. 객체, 즉 엔티티가 갖는 동물의 특징은 '동물' 컴포넌트로 표현하게 되며, 상속이 아니라 Entity가 '동물' 컴포넌트를 갖는 식으로 표현한다. 이렇게 하면, 여러 개의 특징이 필요할 때, 여러 개의 컴포넌트를 갖도록 해서 다중 상속 문제를 회피할 수 있다. 상속으로 표현되는 is-a 관계, 컴포넌트를 참조하는 has-a 관계(또는 uses-a 관계)로 표현을 바꾸어 해결한 셈이다.
여기서 궁금한 점이 생기는 분들이 계실 것 같다. Unity 엔진에서도 마찬가지로 컴포넌트를 활용한다. 그렇다면 유니티도 ECS를 활용한다고 할 수 있을까?
정답은 '그렇지 않다'이다. ECS는 엔티티(Entity), 컴포넌트(Component) 뿐만 아니라 시스템(System)도 추가되어야 한다.
시스템(System)?
기본적으로 유니티의 컴포넌트는 MonoBehaviour 클래스를 상속받는다.
MonoBehaviour를 작성하면, 보통 데이터도 가지면서 이를 처리할 함수도 갖게 된다.

반면, ECS에서는 컴포넌트는 순수하게 데이터만 갖는다. 컴포넌트를 처리하는 함수는 '시스템(System)' 클래스에 존재한다.

특이한 점은, 시스템마다 한 종류의 컴포넌트를 모두 '한 번에' 처리한다는 점이다.
System 1은 모든 이동 컴포넌트를 한 번에 처리하고, System 2는 모든 충돌 컴포넌트를 처리, System 3는 모든 공격 컴포넌트를 처리하는 식이다.

이를 코드로 간략하게 보자면 다음과 같은 식이다.
class MoveSystem
{
MoveComponent moveComponents[];
void update(float time)
{
for (int i = 0; i < count; i++)
{
//moveComponents[i]에 대한 처리
}
}
}
확인해 보면, ECS는 DOD에서 객체를 업데이트하는 패턴과 굉장히 유사하다.
ECS에서는 같은 타입의 컴포넌트를 연속적으로 저장하고 연속해서 처리한다. 그로 인해 메모리 액세스 효율이 증가한다. 이는 DOD에서 캐시를 활용해서 성능을 향상하는 것과 유사하다.
3. ECS와 메모리 모델
그런데, ECS에서는 한 가지 전제가 있다. 바로 같은 타입의 컴포넌트를 연속적으로 저장한다는 점이다. 좀 더 풀어서 말하자면, ECS는 (컴포넌트) 데이터를 한 곳에 모아 한 번에 처리하기 때문에 효율적이다. 그런데 컴포넌트 데이터는 사실 언제 생성되었다가 삭제될지 모르는 데이터이다.
온라인 게임으로 예를 들자면, 하나의 맵에 수백 개의 캐릭터가 존재할 것이고, 이 캐릭터는 플레이어가 접속할 때 새로 추가되고 죽거나 접속이 끊길 때 맵에서 삭제될 것이다. 그런데 그 순간은 사실 정확하게 예측하기 어렵다. A, B, C 캐릭터가 있다면, 이 중에서 어느 캐릭터가 먼저 게임에서 제거될지 알 수 없다. 그렇기 때문에 캐릭터의 컴포넌트도 연속해서 저장해 놓더라도, 언제 무엇이 제거될지 알 수 없어서, 계속 연속적으로 저장해 놓기는 어렵게 된다.
따라서 그에 맞게 메모리를 정리해주어야 한다. 이때 사용하는 방법이 두 가지가 있다.
- Sparse Set 방식: 마인크래프트에서 해당 방식을 활용
- Archetype 방식: Diplomacy Is Not An Option, V Rising 등에서 활용
두 방식은 장단점이 존재하는데, 일반적으로 Sparse Set이 Archetype보다는 좀 더 단순한 구조라고 볼 수 있다.
Sparse Set을 사용하는 대표적인 라이브러리에는 EnTT(C++) 라이브러리 혹은 LeoECS(Unity) 라이브러리가 있다.
반면, Archetype은 상용 클라이언트 엔진에서 많이 활용하는데, 가장 대표적인 게 양대 엔진에 대한 Unity의 DOTS, Unreal Engine의 Mass Entity이 있고, flecs, BEBY 등에서도 활용하고 있다.
특히 위에서 언급한 Diplomacy Is Not An Option, V Rising가 Unity의 DOTS 기반으로 제작되었다고 한다.
3-1. Sparse Set
Sparse Set은 Component의 종류마다 모아서 메모리에 데이터를 Packing 하는 방식이다.
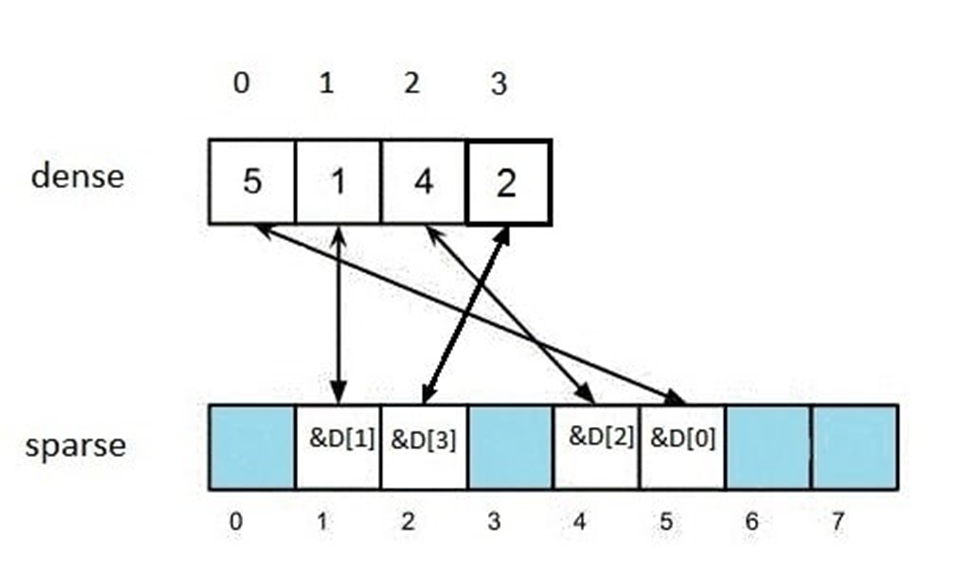
Sparse Set은 자료구조의 이름이기도 한데, 주소를 가리키는 Sparse 배열과 실제 데이터를 담은 Dense 배열을 함께 사용하여 데이터를 저장한다.
실제 데이터, 즉 컴포넌트는 Dense 배열에 연속하여 저장한다. 그래서 탐색 시에도 연속해서 탐색할 수 있다.
반면, 데이터를 검색할 땐 Sparse 배열을 통해 찾을 수 있는데, O(1)의 시간 복잡도로 데이터가 Dense 배열에서 어디에 있는지 찾을 수 있다는 점이 특징이다.
기본적으로 다음과 같은 특징이 있다.
- Component 별로 모여 있으므로(Dense 배열), 추가/삭제가 자유롭다.
- Archetype에 비해 구현이 단순하다.
- 대신, Entity별로 정렬하기는 어렵다.
3.2 Archetype

반면, Archetype은 Component 조합별로 메모리에 데이터를 Packing 하는 방식이다.
무슨 말이냐 하면, A, C, D 컴포넌트를 갖는 Entity끼리 데이터를 연속해서 묶고, C, D 컴포넌트를 갖는 Entity끼리 데이터를 연속해서 묶고, 또 A 컴포넌트만 갖는 Entity끼리 데이터를 묶는다.
실제 게임에서는 CharacterMovement 컴포넌트와 Collider 컴포넌트를 갖는 캐릭터는 캐릭터끼리 종류끼리 연속적으로 데이터를 관리하고, 단순히 Collider만 존재하는 벽은 벽끼리 데이터를 연속해서 저장하는 것이다. 컴포넌트 조합이 같으면 같은 종류라 보고 함께 묶는 것이다.
굉장히 복잡해 보이지만, 이렇게 하면 Entity끼리 묶어놓기 좋다. 같은 Entity의 Component는 함께 저장되니 훨씬 검색하기도 편하다.
그로 인해 다음과 같은 특징이 생긴다.
- Entity가 갖는 조합별로 Packing 하므로, Entity별로 정렬하기 유리하다.
- 조합별로 묶었다 보니 컴포넌트를 추가/삭제할 때 전체를 복사해야 한다.
- Sparse Set 방식에 비해 복잡하다.
여기서 두 번째는 약간 설명이 필요한데, A, C, D 컴포넌트를 갖는 액터에서 C 컴포넌트를 제거하고 싶다면, 단순히 컴포넌트를 제외하는 것으로 끝나지 않는다.
A, C, D 컴포넌트를 갖는 액터끼리 Character라는 곳에 데이터를 모아서 저장했다고 하자. 여기서 C를 제외하면 조합 자체가 A, C, D에서 A, D 컴포넌트 조합으로 바뀌어 버리게 된다.
따라서 A, C, D 컴포넌트를 모아놓은 곳에서 액터를 제거해고, 아예 A, D 컴포넌트 조합을 갖는 다른 집합으로 데이터를 옮겨야 한다. 아예 메모리 상에서 데이터의 위치를 옮겨야 하니, 전체 컴포넌트를 복사해야 하는 것이다. 이 점은 Archetype에서 컴포넌트를 추가할 때에도 동일하다.
Unreal, Unity Engine에서 자체적으로 Archetype 방식을 지원하고 있긴 하지만, 복잡하고 배우는 데에 많은 시간을 요구한다는 문제가 있다(6개월 이상의 학습 필요). 따라서 프로젝트의 필요에 따라 Sparse Set 방식을 채택하기도 한다.
4. ECS의 특징
ECS를 채택하면 좋은 점 하나가 있다.
바로 메인 루프 하나만 봐도 게임 전체의 구조가 보인다는 점이다.
void Game::update(const double time)
{
m_move_system.update(time, m_registry);
m_ai_system.update(time, m_registry);
m_collisition_system.update(time, m_collideables);
}ECS에서 각 컴포넌트는 컴포넌트 데이터로 취급되는데, 컴포넌트에 대한 시스템이 존재한다. 이 시스템이 해당하는 컴포넌트에 대해 루프를 돌며 처리해 주는 방식이다.
메인 루프에서는 각 시스템별 업데이트 함수를 순서대로 호출해 준다(중앙에서 업데이트가 관리됨). Unity의 MonoBehaviour 시스템에서는 컴포넌트마다 Update 함수가 돌아가지만, ECS에서는 메인 루프에서 게임 로직이 모두 시작된다. 따라서, ECS 시스템을 활용하면 메인 루프만 보아도 게임이 모두 보인다고 할 수 있다.
이때 좋은 점은, 메인 루프에서의 처리 순서는 코드에서 명확하게 명시된다는 점이다. 위 코드에서는 movement 처리, ai 시스템 처리, 충돌 처리를 순서대로 수행하며 이 순서는 절대 바뀔 일이 없다.
실행 순서가 명확히 결정되어 있기 때문에, 다른 시스템 변경에 의해 알 수 없는 버그가 생기는 일이 확실히 줄어든다.
또한, 초기에 구조를 잡는 데에는 많은 시간이 걸리지만 어느 정도 궤도에 오르면 컴포넌트를 조합하여 다양한 요소를 추가하기 쉽다. 실제로, 오버워치 등과 같은 게임에서 ECS를 활용하여 개발하였을 때 강연한 점을 보면 각 컴포넌트 간의 커플링이 줄어서 확장성이 높아졌다는 평가도 많다.
나중에 시간이 난다면, 다음 영상도 보는 것을 추천한다. 오버워치 개발 시에 ECS를 활용하여 개발하였는데, 이에 관한 설명을 영상에서 상세히 하고 있어 대형 게임의 아키텍처를 구성할 때 도움이 될 것으로 보인다.
https://www.youtube.com/watch?v=W3aieHjyNvw
참고 자료
데이터 지향 설계
- Eric Friedman, Unreal Engine - Data Oriented Design and the Cost of Tick
ECS
Board To Bits Games, Entity Component System Overview in 7 Minutes
ECS : Unity ECS, Unity DOTS (초급 강좌)
Sparse Set
AlexCheero, ECS: under the hood
skypjack, ECS back and forth part 2 - Where are my entities?
GeeksforGeeks, Sparse Set
'Architects, Design Patterns' 카테고리의 다른 글
| 인터페이스와 구현을 분리해도, 인터페이스를 변경해야 하는 경우가 온다면?(책 '객체지향의 사실과 오해'를 읽으며) (1) | 2025.09.13 |
|---|---|
| 유니티 C# 싱글턴 패턴 + Lazy를 이용한 버전 (7) | 2020.08.30 |

댓글